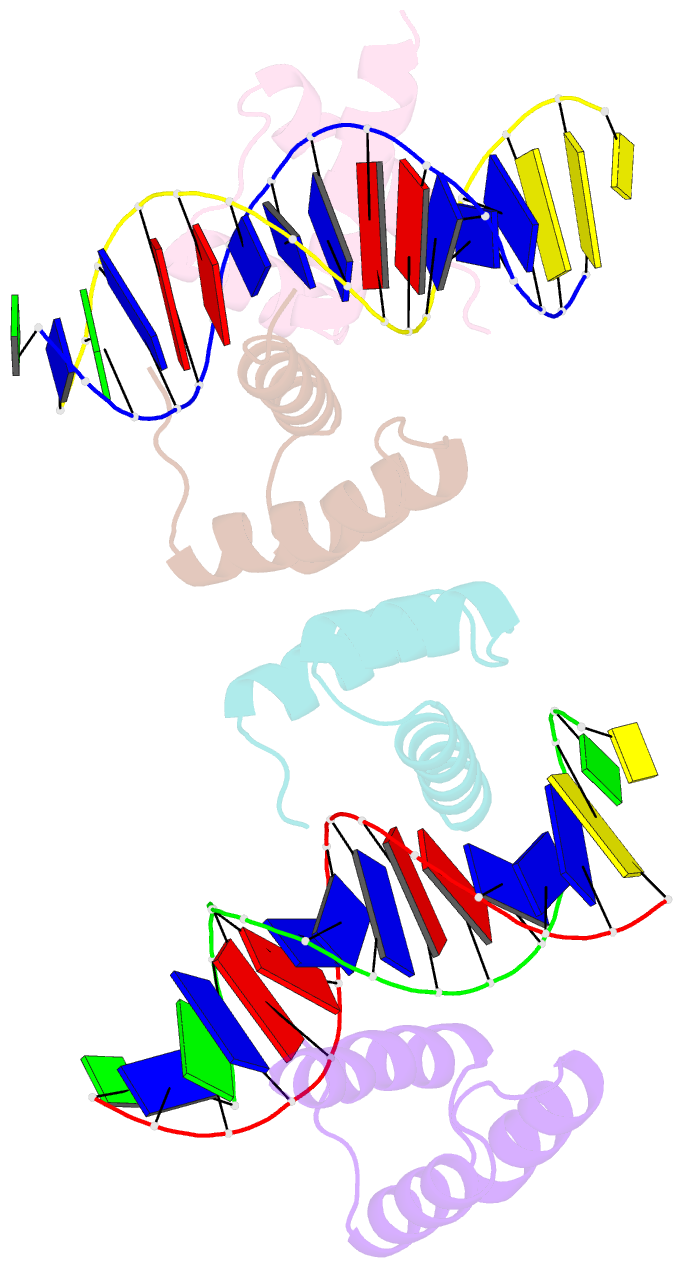
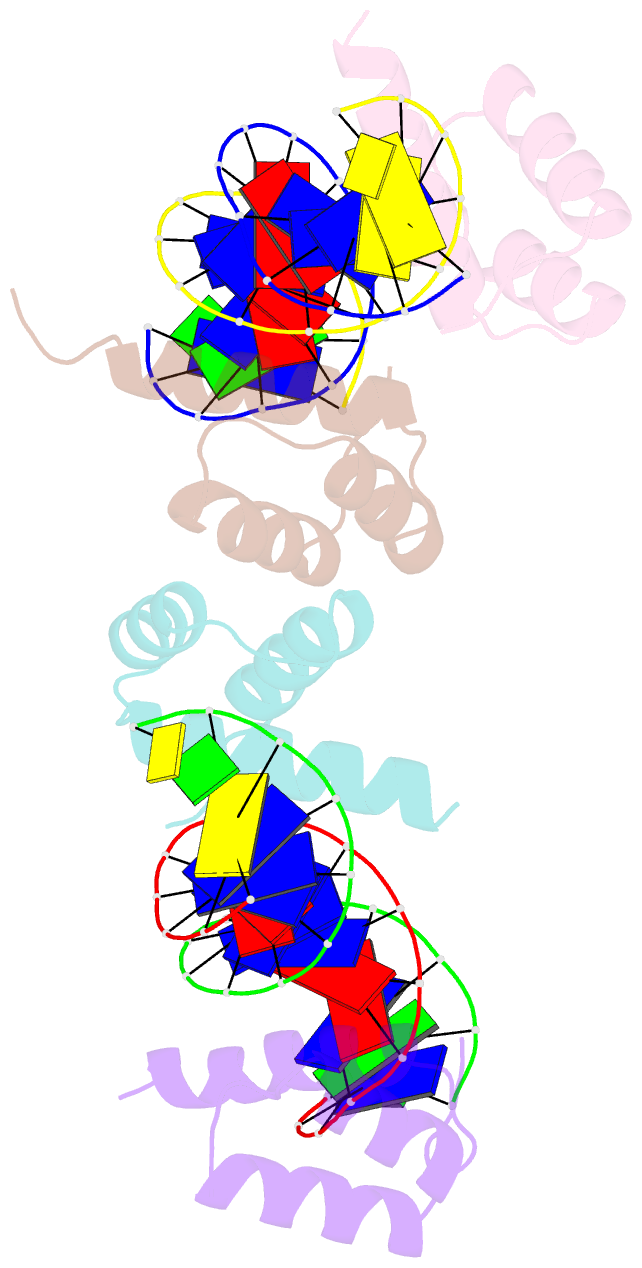
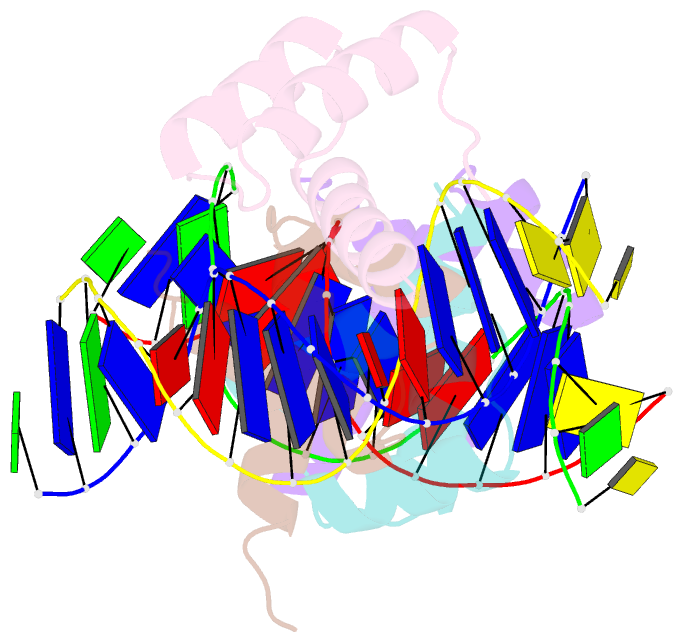
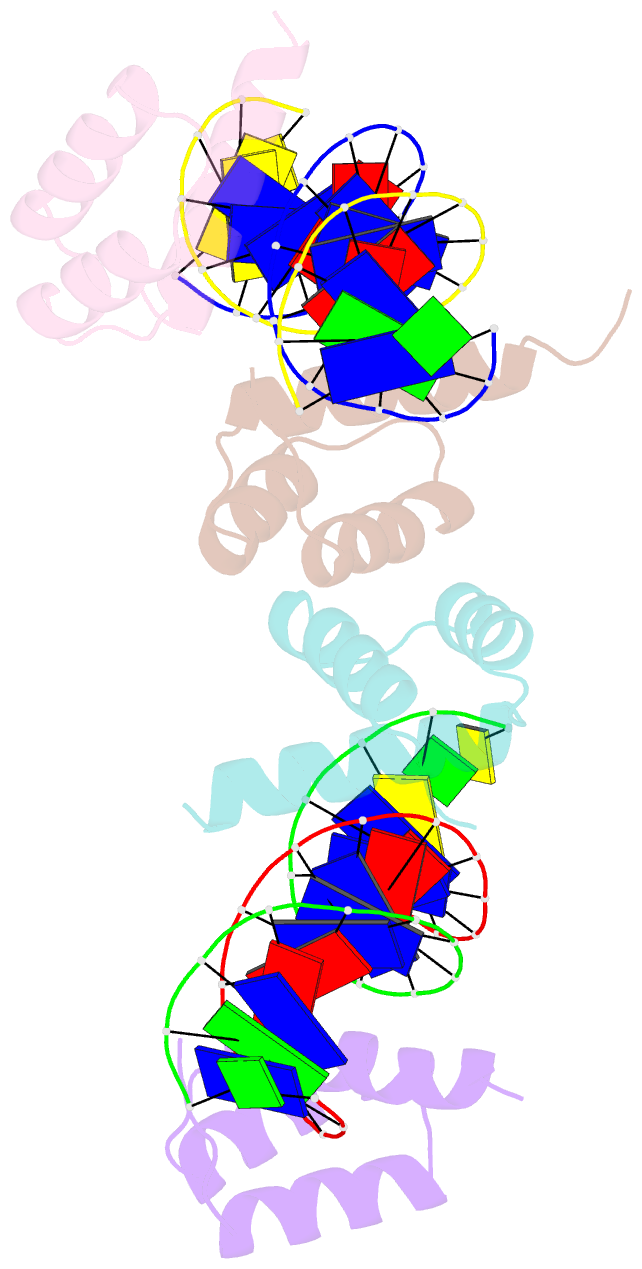
Summary information and primary citation
- PDB-id
- 4qtr; SNAP-derived features in text and JSON formats;
DNAproDB
- Class
- de novo design-DNA
- Method
- X-ray (3.2 Å)
- Summary
- Computational design of co-assembling protein-DNA nanowires
- Reference
- Mou Y, Yu JY, Wannier TM, Guo CL, Mayo SL (2015): "Computational design of co-assembling protein-DNA nanowires." Nature, 525, 230-233. doi: 10.1038/nature14874.
- Abstract
- Biomolecular self-assemblies are of great interest to nanotechnologists because of their functional versatility and their biocompatibility. Over the past decade, sophisticated single-component nanostructures composed exclusively of nucleic acids, peptides and proteins have been reported, and these nanostructures have been used in a wide range of applications, from drug delivery to molecular computing. Despite these successes, the development of hybrid co-assemblies of nucleic acids and proteins has remained elusive. Here we use computational protein design to create a protein-DNA co-assembling nanomaterial whose assembly is driven via non-covalent interactions. To achieve this, a homodimerization interface is engineered onto the Drosophila Engrailed homeodomain (ENH), allowing the dimerized protein complex to bind to two double-stranded DNA (dsDNA) molecules. By varying the arrangement of protein-binding sites on the dsDNA, an irregular bulk nanoparticle or a nanowire with single-molecule width can be spontaneously formed by mixing the protein and dsDNA building blocks. We characterize the protein-DNA nanowire using fluorescence microscopy, atomic force microscopy and X-ray crystallography, confirming that the nanowire is formed via the proposed mechanism. This work lays the foundation for the development of new classes of protein-DNA hybrid materials. Further applications can be explored by incorporating DNA origami, DNA aptamers and/or peptide epitopes into the protein-DNA framework presented here.